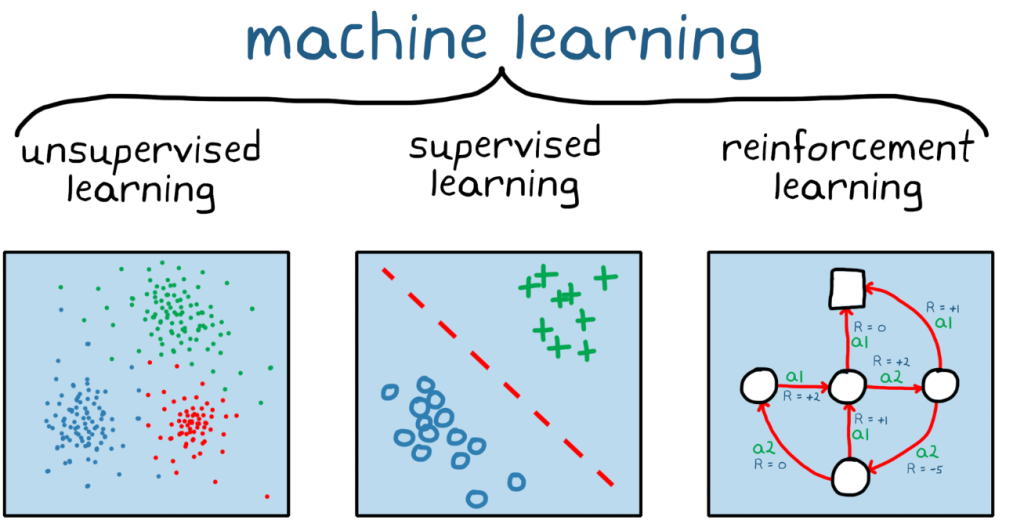
Understanding Unsupervised Learning
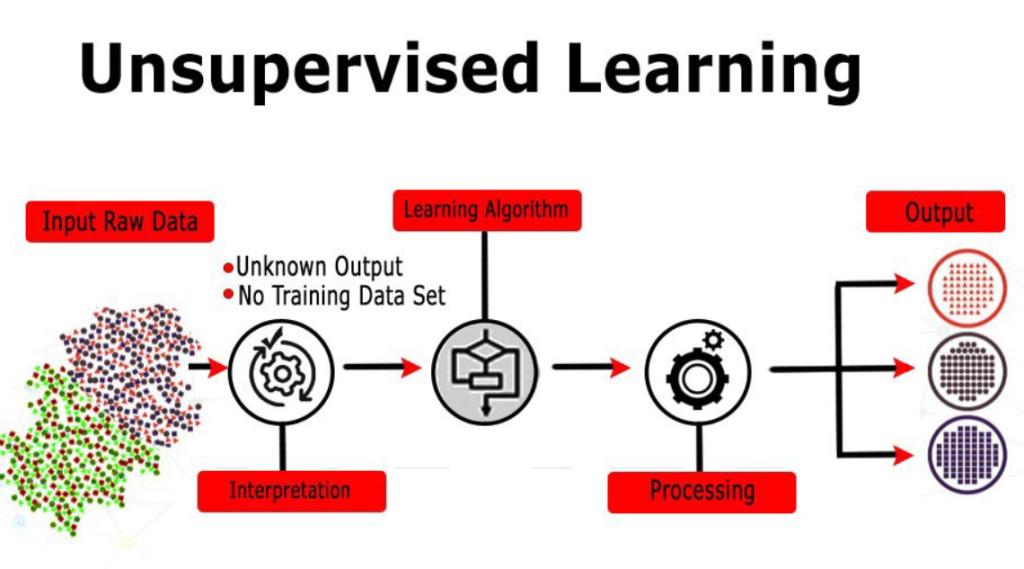
Unlike supervised learning, where models are trained on labeled data, unsupervised learning deals with unlabeled data. The goal is to discover hidden patterns, structures, or relationships within the data without any prior knowledge. This makes it a powerful tool for exploring and understanding complex datasets.
Key Concepts
- Clustering: Grouping similar data points together.
- Dimensionality Reduction: Reducing the number of features while preserving essential information.
- Association Rule Learning: Discovering relationships between items in a dataset.
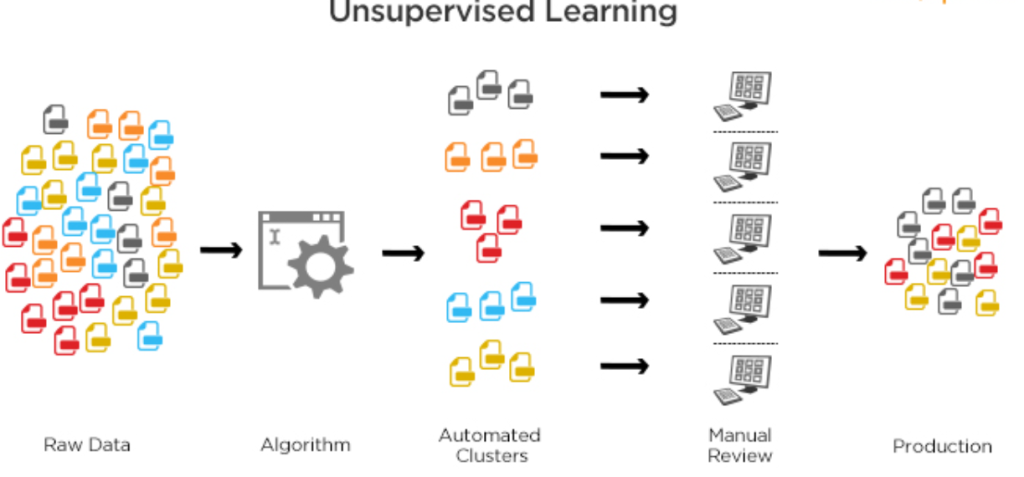
Clustering
Clustering is a technique to group similar data points into clusters.
- K-means Clustering: One of the most popular algorithms, it partitions data into K clusters based on the mean distance between data points.
- Hierarchical Clustering: Creates a hierarchy of clusters, starting from individual data points and merging them based on similarity.
- DBSCAN: Density-Based Spatial Clustering of Applications with Noise, groups together points that are closely packed together and marks outliers as noise. 1. github.com github.com
Example: Customer segmentation based on purchasing behavior.
Dimensionality Reduction
Dimensionality reduction is used to simplify high-dimensional data by reducing the number of features.
- Principal Component Analysis (PCA): Projects data onto a lower-dimensional space while preserving most of the variance.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): Non-linear technique for visualizing high-dimensional data in a lower-dimensional space.
Example: Visualizing complex datasets in 2D or 3D for better understanding.
Association Rule Learning
Association rule learning finds relationships between items in a dataset.
- Apriori Algorithm: Efficiently generates frequent itemsets and association rules.
Example: Market basket analysis to identify products frequently bought together.
Applications of Unsupervised Learning
- Customer segmentation: Grouping customers based on behavior.
- Image and document clustering: Organizing large collections of images or documents.
- Anomaly detection: Identifying unusual data points.
- Feature engineering: Creating new features from existing ones.
- Recommendation systems: Suggesting items based on user preferences.
Challenges and Considerations
- Evaluation: Unlike supervised learning, evaluating unsupervised models can be challenging due to the lack of ground truth.
- Interpretation: Understanding the meaning of discovered patterns can be complex.
- Algorithm Selection: Choosing the right algorithm depends on the dataset and the problem.
Conclusion
Unsupervised learning is a valuable tool for exploring and understanding data. By discovering hidden patterns and structures, it can provide insights that would be difficult to obtain through other methods. Experiment with different techniques and evaluate the results to find the best approach for your specific problem.
