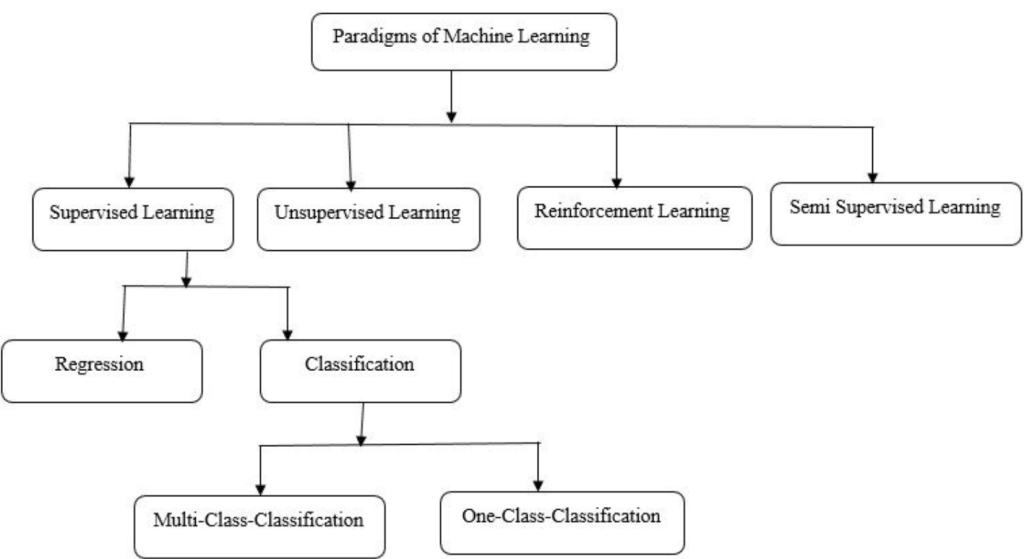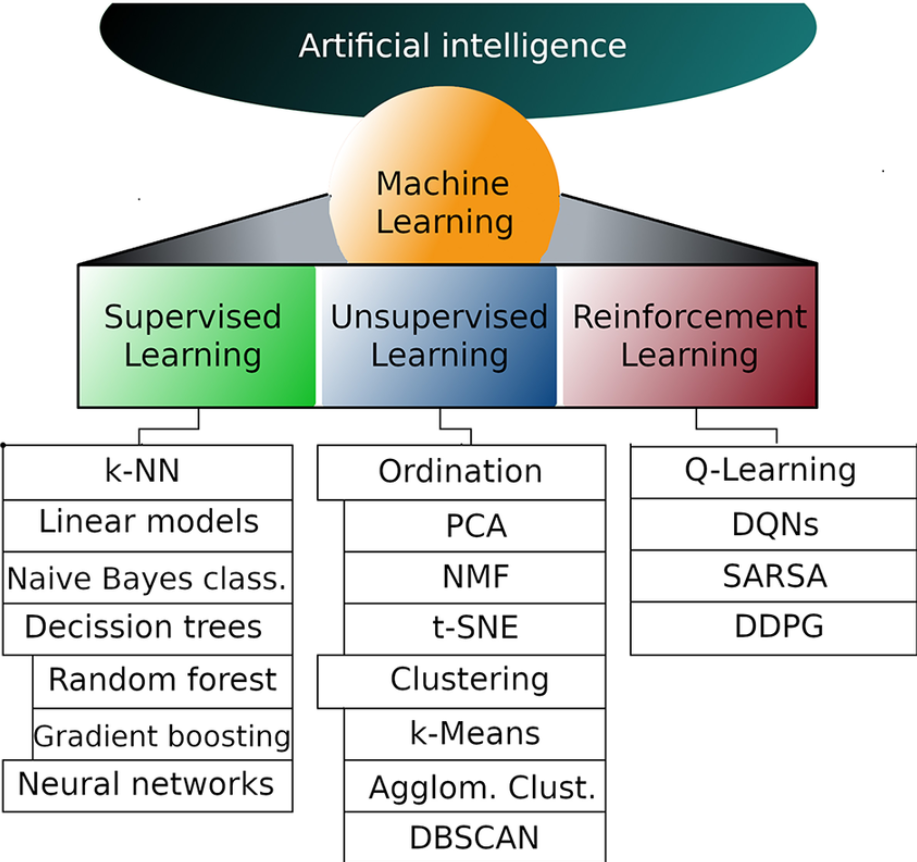
Machine Learning (ML) is a core subset of Artificial Intelligence (AI), and its diverse methodologies can be categorized into three primary branches: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Each of these branches encompasses various techniques and algorithms tailored to specific types of data and problems. The image above provides a visual representation of these branches and their associated subbranches, offering a concise overview of the landscape of Machine Learning.
1. Supervised Learning
Supervised Learning is perhaps the most widely used branch of Machine Learning. It involves training a model on a labeled dataset, where the input data is paired with the correct output. The goal is for the model to learn to predict the output for new, unseen data based on this training.
- k-Nearest Neighbors (k-NN): A simple, instance-based learning method where predictions are made based on the closest examples in the feature space.
- Linear Models: These include linear regression for continuous data and logistic regression for classification tasks.
- Naive Bayes Classifier: A probabilistic classifier based on applying Bayes’ theorem with strong (naive) independence assumptions between the features.
- Decision Trees: A model that makes decisions by splitting data into subsets based on feature values, often visualized as a tree.
- Random Forest: An ensemble method that builds multiple decision trees and merges them to produce a more accurate and stable prediction.
- Gradient Boosting: Another ensemble technique that builds models sequentially, each one correcting the errors of its predecessor.
- Neural Networks: Inspired by the human brain, these are deep learning models used for both classification and regression tasks, especially where data patterns are complex.
2. Unsupervised Learning
Unsupervised Learning is used when the data is not labeled, meaning the model must find patterns and relationships in the data without guidance. This branch is essential for tasks like clustering, dimensionality reduction, and anomaly detection.
- Ordination: Refers to methods like Principal Component Analysis (PCA), which is used for dimensionality reduction, and Non-negative Matrix Factorization (NMF), which decomposes data into additive components.
- t-SNE (t-Distributed Stochastic Neighbor Embedding): A technique for reducing the dimensionality of data while preserving its structure, often used for visualizing high-dimensional datasets.
- Clustering: Techniques for grouping data points that are similar to each other.
- k-Means: A popular clustering algorithm that partitions data into k distinct clusters based on distance to the centroid.
- Agglomerative Clustering: A hierarchical method that builds nested clusters by merging or splitting them successively.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): A clustering algorithm that groups together points that are closely packed together, marking points in low-density regions as outliers.
3. Reinforcement Learning
Reinforcement Learning (RL) is a branch where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. Unlike Supervised Learning, RL doesn’t rely on labeled input/output pairs but instead learns from the consequences of its actions.
- Q-Learning: A value-based learning algorithm that seeks to find the best action to take given the current state.
- Deep Q-Networks (DQNs): Combines Q-Learning with deep neural networks to handle high-dimensional input spaces, such as those from raw pixels in games.
- SARSA (State-Action-Reward-State-Action): A variation of Q-Learning that updates the action-value function based on the action actually taken.
- DDPG (Deep Deterministic Policy Gradient): A model-free, off-policy algorithm used for environments with continuous action spaces, combining the benefits of both policy gradient methods and Q-learning.
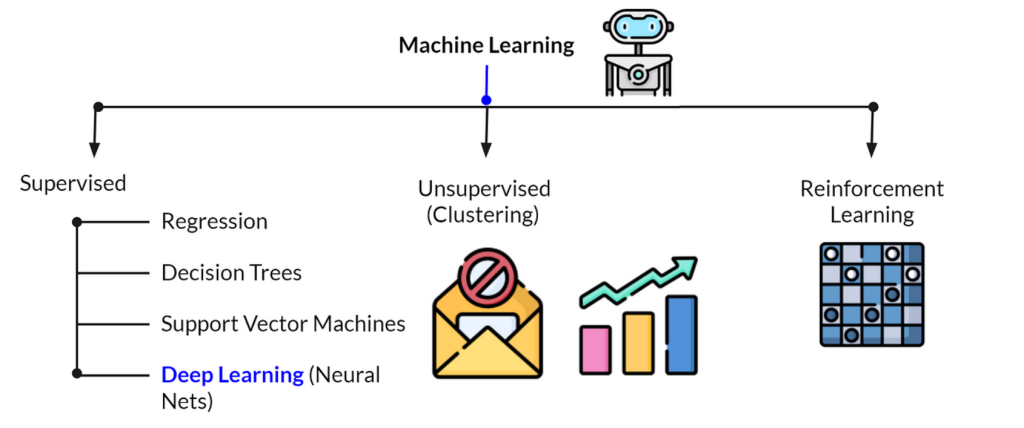
The subbranches of Machine Learning (ML) are diverse and cover various approaches to teaching machines to learn from data. Here are the main subbranches:
1. Supervised Learning
- Classification: Assigns input data to predefined categories or labels (e.g., spam vs. non-spam emails).
- Regression: Predicts continuous numerical values from input data (e.g., predicting house prices).
- Neural Networks: A family of algorithms inspired by the human brain, used for both classification and regression tasks.
2. Unsupervised Learning
- Clustering: Groups similar data points together without predefined labels (e.g., customer segmentation).
- Dimensionality Reduction: Reduces the number of input features while retaining essential information (e.g., Principal Component Analysis, PCA).
- Anomaly Detection: Identifies unusual or rare data points that deviate from the norm (e.g., fraud detection).
- Association Rules: Discovers relationships between variables in large datasets (e.g., market basket analysis).
3. Reinforcement Learning
- Model-Based Reinforcement Learning: Uses a model of the environment to plan actions and optimize rewards.
- Model-Free Reinforcement Learning: Learns actions directly from experience without relying on a model of the environment.
- Policy Gradient Methods: Optimizes the decision policy directly rather than focusing on the value of actions.
- Q-Learning: A value-based method that estimates the value of actions to maximize future rewards.
4. Semi-Supervised Learning
- Combines a small amount of labeled data with a large amount of unlabeled data to improve learning efficiency.
5. Self-Supervised Learning
- Uses the data itself to generate labels for training, often applied in tasks where labeled data is scarce.
6. Transfer Learning
- Leverages knowledge gained from one task to enhance learning performance on a related but different task.
7. Deep Learning (Subset of ML)
- Convolutional Neural Networks (CNNs): Specialized for processing grid-like data such as images, widely used in image recognition.
- Recurrent Neural Networks (RNNs): Designed for sequential data, like time series or text, to capture temporal dependencies.
- Long Short-Term Memory Networks (LSTMs): A type of RNN that can remember information over long sequences, used in tasks like language modeling.
- Generative Adversarial Networks (GANs): Composed of two neural networks competing against each other to generate new, synthetic data resembling the input data.
- Autoencoders: Unsupervised learning models that learn efficient representations of data, often used for dimensionality reduction and noise reduction.
These subbranches highlight the versatility of machine learning, covering a wide range of methodologies and applications, from pattern recognition to predictive analytics and beyond.